Amazon Bedrock是一個完全托管的服務,提供對各種高性能基礎模型(FMs)的訪問,並簡化了RAG系統的實施。生成合成數據的過程包括加載數據,對其進行分塊,使用LLM生成問題和答案,並進行數據集的精煉,以確保多樣性和相關性。使用LangChain進行自動化,這是一個開源的Python庫,用於協調數據集生成過程,允許模塊化集成LLMs和其他組件。文章強調了使用評論代理來評估生成問題和答案的質量的重要性,確保它們與提供的上下文相關且有根據。為了保持質量,建議將合成數據與真實世界數據相結合,選擇合適的模型,實施強大的質量保證,並在數據集生成過程中進行迭代。總結起來,合成數據集對於加速RAG系統的開發非常有價值,但其質量取決於底層模型和提示的使用。持續的精煉和評估對於有效實施至關重要。
重點摘要:
-如何使用Amazon Bedrock和Anthropic Claude模型來生成合成數據集,以用於評估檢索增強生成(RAG)系統。
– 生成合成數據對於評估RAG系統至關重要,特別是在早期開發階段難以獲得高質量真實數據集時。
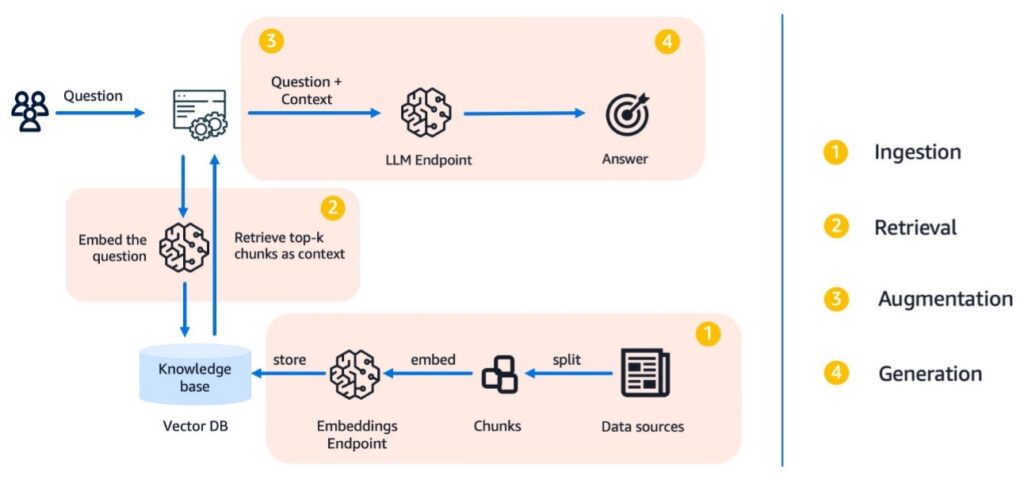
– RAG工作流程包括數據載入、嵌入生成、檢索相關片段以及使用大型語言模型(LLM)生成答案。
– Amazon Bedrock是一個完全托管的服務,提供對各種高性能基礎模型(FM)的訪問,並簡化了RAG系統的實現。
– 合成數據生成過程包括數據加載、切片、使用LLM生成問題和答案,以及對數據集進行精煉以確保多樣性和相關性。
– 使用開源的Python庫LangChain可以自動化數據集生成過程,實現LLM和其他組件的模塊化集成。
– 文章強調使用評論代理來評估生成的問題和答案的質量,確保它們與提供的上下文相關且有根據。
– 為了保持質量,建議將合成數據與真實數據結合使用,選擇合適的模型,實施強大的質量保證,並在數據集生成過程中進行迭代。
– 合成數據集對於加速RAG系統的開發非常有價值,但其質量取決於底層模型和提示的使用。持續的精煉和評估對於有效實施至關重要。