在AI應用逐漸普及的今天,透過大型語言模型(LLM)提供推理服務的需求越來越高。隨著這些模型在各種應用領域的價值逐漸顯現,如何有效控制運行成本成為關鍵。事實上,善用自動調整技術,不僅能夠滿足使用需求,還能讓企業節省GPU運行費用。最近,Google推出了一套針對GKE(Google Kubernetes Engine)的自動調整建議,幫助企業更靈活地管理LLM推理工作負載資源。
文章重點
GKE作為Google的受管容器編排服務,提供了一個便捷的平臺來部署、管理和調整LLM推理工作負載。透過整合「水平 Pod 自動調整」(Horizontal Pod Autoscaler, HPA),企業可以讓模型服務根據流量自動擴容或縮減,有效降低成本。透過微調HPA的設置,企業可以精確地將硬體成本與流量需求匹配,從而達到理想的推理服務效能。
多種指標的探索:哪種最適合LLM推理自動調整?
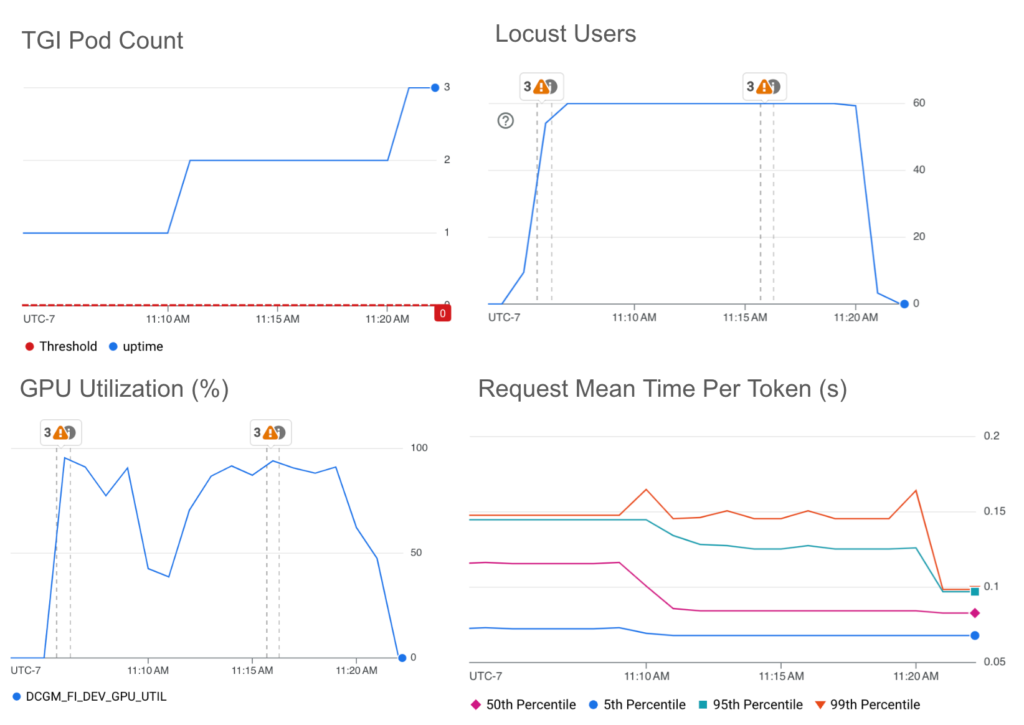
為了找到最佳自動調整指標,Google團隊進行了多次實驗,並整理出GPU推理自動調整的最佳實踐。這些實驗中使用的模型服務器為Text-Generation-Inference (TGI) 和 HPA,相關實驗結果同樣適用於vLLM等具備類似指標的推理服務器。以下幾項指標對於自動調整的效果有所不同:
- GPU 使用率
- 通常情況下,CPU或記憶體利用率作為指標適合自動調整。但由於LLM推理服務主要依賴GPU運行,這些指標無法完整反映資源的實際使用狀況。GPU利用率指標顯示的是GPU活躍的時間,但這並不能與推理請求的處理效率一一對應。結果發現,單純依靠GPU使用率可能會導致過度擴容,進而增加成本。
- 批量大小(Batch Size)
- TGI 提供了LLM服務器特定的指標,例如批量大小(tgi_batch_current_size),即每次推理運行時處理的請求數量。研究發現,批量大小與每Token的平均處理時間有直接關聯,這項指標在以低延遲為優先的情境下表現良好。然而,因為批量大小隨請求量的變動而有所不同,需在略低於最大批量大小的情況下設定,以便在流量增加時能觸發擴容。
- 佇列大小(Queue Size)
- 另一個有效的指標是佇列大小(tgi_queue_size),代表等待處理的請求數量。實驗顯示,佇列大小與平均處理時間的延遲呈正相關,高佇列大小顯示了較大的延遲。佇列大小適合以高吞吐量為目標的應用,但因為它僅顯示等待的請求數量,相比批量大小無法達到較低的延遲。
如何設定最佳的門檻值?
為了確定最佳的自動調整門檻值,Google 團隊利用了ai-on-gke工具進行了測試,以達到不同的性能需求。例如:
- 針對高吞吐量需求:門檻值設定為佇列大小在吞吐量穩定且延遲增加的情況下。
- 針對低延遲需求:則設定批量大小門檻在約80%的最佳吞吐量情境下自動調整。
實驗結果顯示,在模擬150%突發流量的情境中,佇列和批量大小的門檻設置能有效維持穩定的推理性能,且成本控制在可接受的範圍內。
更聰明的自動調整帶來的效益
在本次研究中,Google 團隊指出,依賴GPU利用率進行自動調整可能會導致過度擴容,增加不必要的成本。相對地,使用LLM服務器特定指標進行自動調整,能更準確地控制延遲或吞吐量,使硬體成本和效能需求達成平衡。對於以低延遲為目標的推理應用,批量大小是一個不錯的選擇,而高吞吐量應用則適合使用佇列大小。
如果有興趣了解如何配置這些自動調整指標,可以參考《在Google Kubernetes Engine上配置LLM工作負載的GPU自動調整》,學習如何在GKE環境中應用最佳實踐來管理推理工作負載。


