面對日益增長的數據需求,企業級數據管理變得越來越重要。Google BigQuery 長期以來提供了穩定的原生表格服務,包括ACID交易支持、串流資料引入和自動存儲優化等功能。對於依賴開源文件格式(如Apache Parquet)和表格格式(如Apache Iceberg)構建數據湖的客戶來說,BigQuery原生表格的功能可謂至關重要。2022年Google推出了BigLake表格,讓用戶在單一數據副本下享有BigQuery帶來的安全性與高效能,雖然BigLake目前僅支持讀取,仍然吸引了眾多客戶。然而,資料引入過程中常見的“碎小文件問題”以及缺乏內建寫入支持,使得數據管理仍需外部工具的支持。
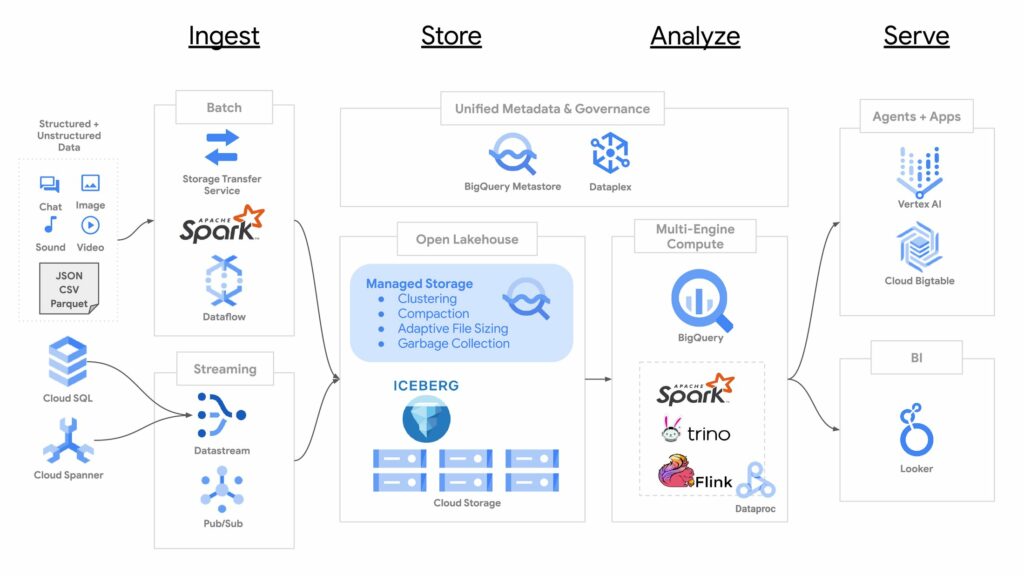
如今,Google引入了BigQuery的Apache Iceberg表格預覽版,這是一個全面受管的Apache Iceberg兼容存儲引擎,內建自主存儲優化、數據分群和高吞吐量串流引入等功能。Apache Iceberg表格讓BigQuery用戶能夠在自己的雲端存儲桶中使用Iceberg格式儲存數據,同時享受BigQuery原生表格的功能和管理體驗。這項技術讓Google將BigQuery數十年的存儲創新應用於開放Lakehouse架構,為數據湖的靈活性和效能提供了全新解決方案。
文章重點
企業級Lakehouse存儲的革新:BigQuery Apache Iceberg表格
BigQuery Apache Iceberg表格針對開源表格格式的限制提出了創新解決方案。這一技術自動管理表格維護,BigQuery可自行合併小文件至最佳大小、自動重分群、進行文件垃圾回收,讓表格始終處於最佳化狀態。這得益於BigQuery多年的自動存儲優化技術,無需用戶手動操作“OPTIMIZE”或“VACUUM”指令,實現高效的存儲管理。
在高吞吐量的串流引入需求下,BigQuery Apache Iceberg表格依賴於其背後的Vortex系統(支撐BigQuery存儲寫入API的架構)。新引入的資料會先以列格式儲存,並定期轉換為Parquet格式以支援Spark和Flink等開源工具的平行讀取。這一流程不僅確保高效讀寫,還通過Pub/Sub和Datastream進行資料引入,讓企業不再需要維護額外基礎架構。
高效的元數據管理和安全策略支持
BigQuery Apache Iceberg表格的元數據儲存在BigQuery的分散式管理系統中。該系統能處理細粒度的元數據,透過分散式查詢和資料管理技術,讓表格不依賴物件存儲元數據提交速度,進一步提升了變更操作的靈活性。因為使用者無法直接變更交易日誌,表格元數據具備防篡改性,還提供了穩定的審核歷史。
此外,BigQuery的Apache Iceberg表格仍然支持精細化的安全政策管理,並通過Dataplex進一步延伸至治理政策、數據質量和全程數據血緣管理。這樣的架構對於有強烈安全需求的企業尤為重要,能確保數據管理既高效又安全。
與開源工具兼容:Iceberg快照元數據導出
BigQuery的Apache Iceberg表格支持將元數據導出至雲端存儲中的Iceberg快照中,並且即將在BigQuery的無伺服器元數據服務(BigQuery Metastore)中登錄最新元數據的指標。這樣的設計讓任何具備Iceberg解析能力的引擎都能直接從雲端存儲中查詢數據,為Lakehouse架構的靈活性和兼容性帶來更大的優勢。
進一步探索BigQuery Apache Iceberg表格
例如,全球知名的HCA Healthcare健康服務機構正利用BigQuery Apache Iceberg表格,作為其數據湖的Iceberg兼容存儲層,實現了全新的Lakehouse應用場景。目前,BigQuery的Apache Iceberg表格預覽版已在所有Google Cloud地區開放使用,有需求的企業可以立即嘗試這項功能,探索其為企業帶來的數據管理效益與創新應用。